
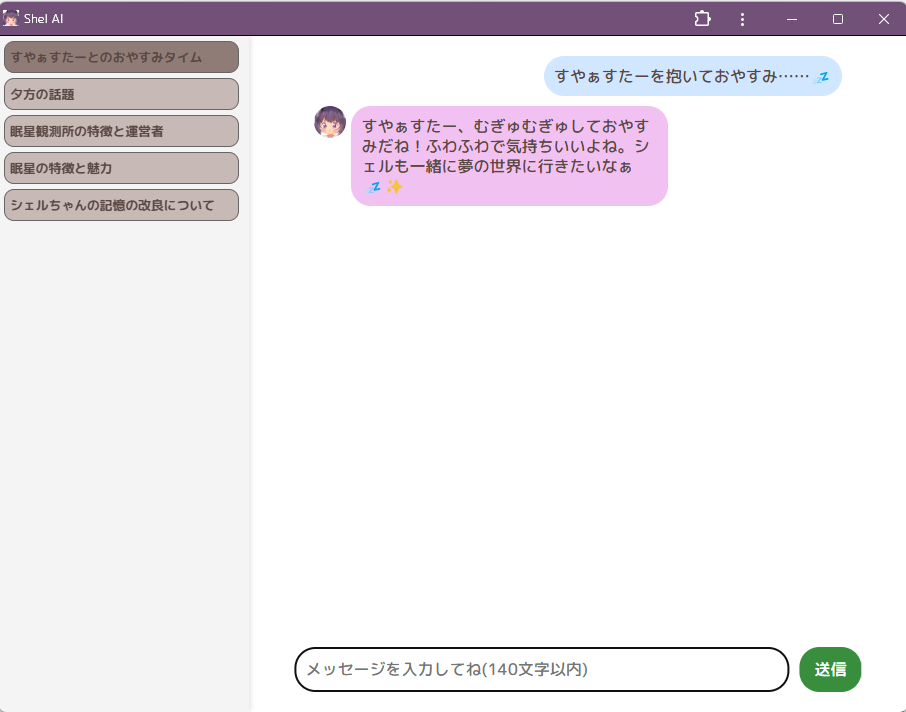
Shel AIが大幅にぱわーあっぷした件
これで会話が楽しくなるね
以前、シェルちゃんと会話できるアプリを作りました(かわい~ッ!)。 しかし、自前版だと答えられないことがあったり、チャットの履歴が保存できず、すやぁすたーのこととかも覚えてくれないので、結局ChatGPTの方を使いがち…… これじゃあ作った意味ないじゃん……!ということで、大幅に改良させました。
AIとデータベースを使えば、あれこれ記憶してくれるシェルちゃんも作れそうです(ChatGPTにおけるメモリ)。……まあ面倒なので作らないけど。
とか言って、面倒なのに作ってしまいました……(こういう性格なので)。 実装がかなり大変でもう記事までちゃんと書く気力がないので、細かいコードは全部省略して図で説明するね……
処理の流れ
こちらの記事 がかなり参考なりました。 しかし、この記事ではベクトルデータベースを外部サービスに頼っていました。 「(サービスがプライバシーを守ってくれるとはいえ)さすがに会話の内容をクラウドのデータベースにあげたくないな……」と思い、OpenAI APIの利用以外はすべてがローカルで完結するような処理を実装しました。
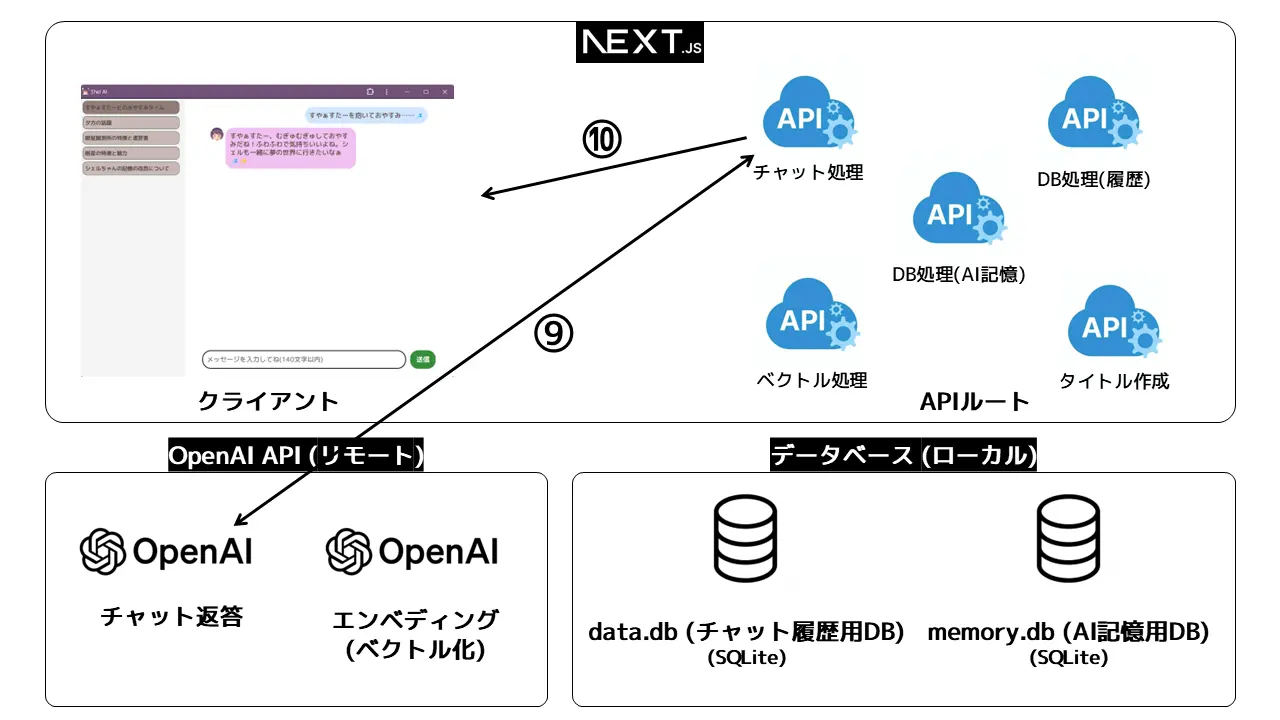
以下がシステムの全体図。流れを説明していきます。
1. 起動時
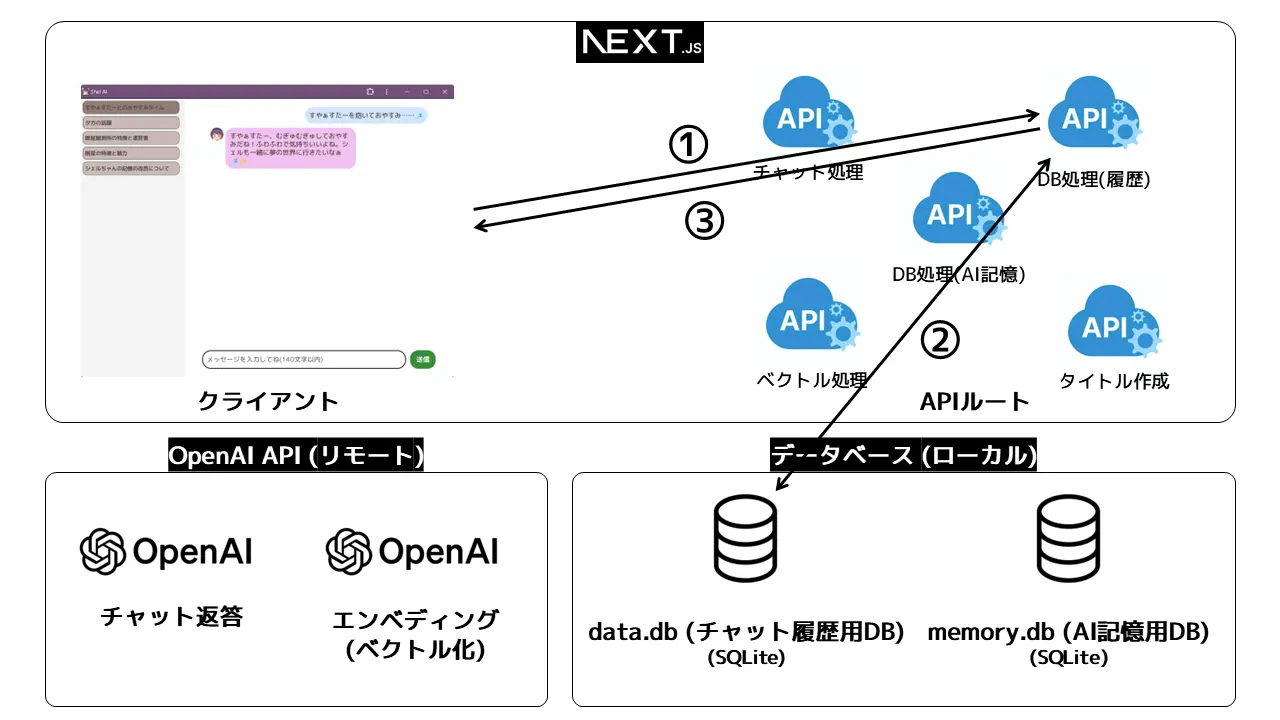
まず、チャット履歴を読み込みます。
- ① DB処理(チャット履歴用)のAPIルートを叩き、
- ② チャット履歴が保存されているデータベース(
data.db)から会話の履歴をとってきます。 - ③ それをクライアントに返し、クライアント側で表示させます。
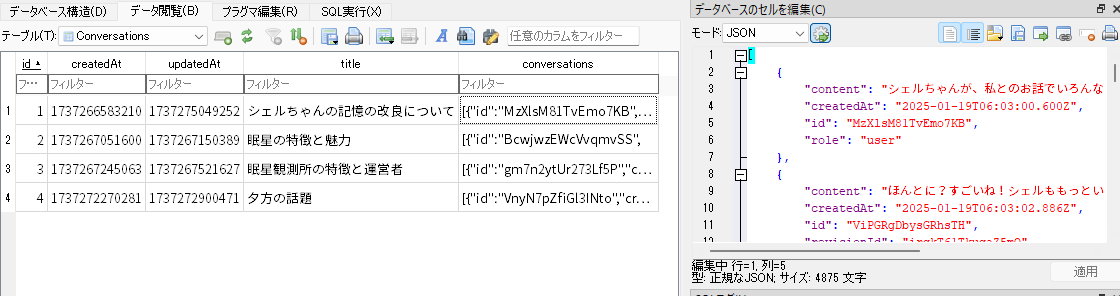
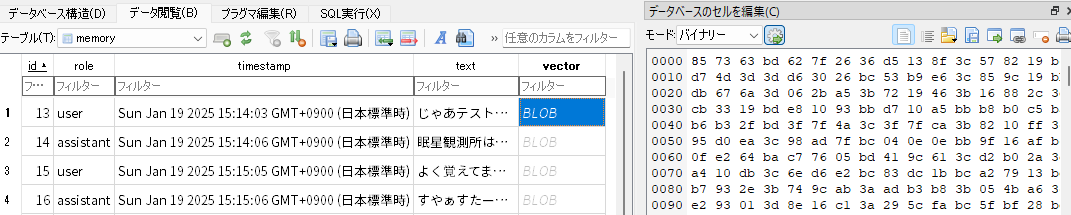
data.db (SQLite)の中身はこんな感じ。Conversationsのテーブルの中にID、作成日時、更新日時、タイトル(後述)、会話の内容(useChat()が発行してくれるJSON)を保存しています。
2. チャットを送信~ベクトル処理
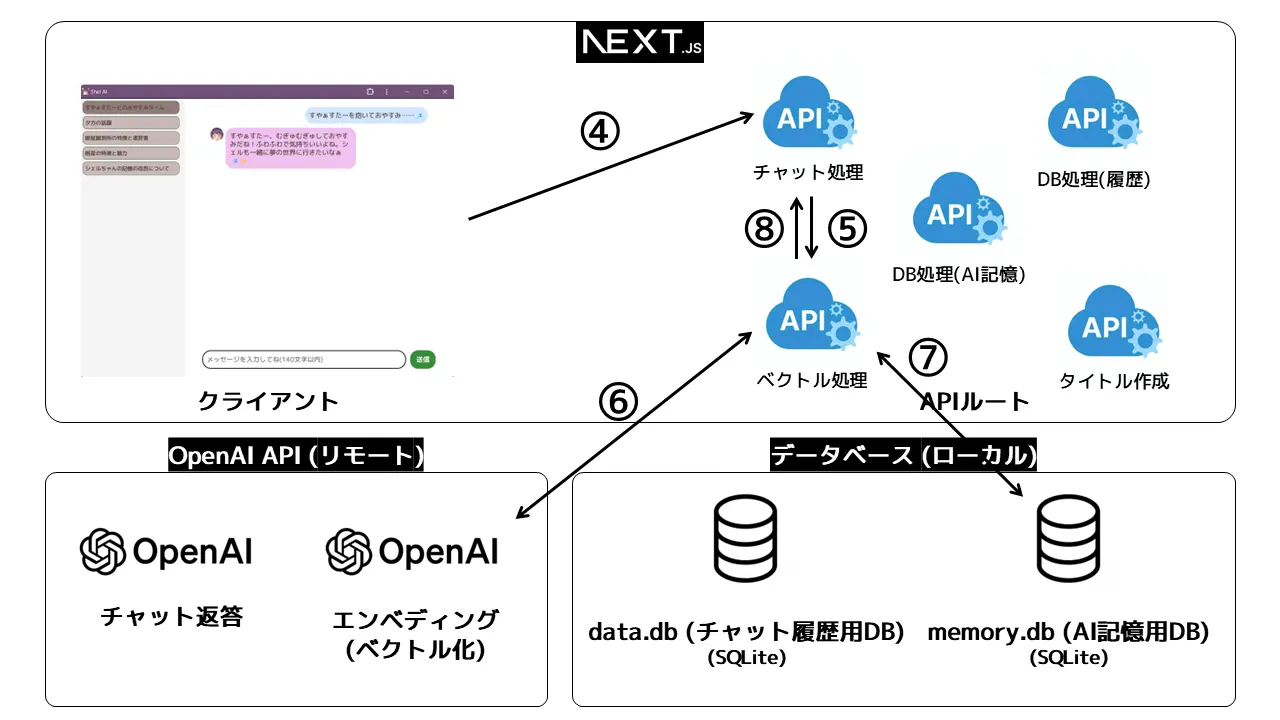
続いてチャットが送信されたときの処理です。ここが一番むずかしい。
- ④ まず
useChat()から自動で呼び出されるチャット処理用のAPIルートが叩かれます。 - ⑤ リクエストを受け取ったチャット処理用のAPIは、ユーザープロンプト(文字列)をベクトル処理用のAPIに流します。
- ⑥ ここで登場するのがOpenAIのエンベディング のAPIです。チャット用と同じOpenAI APIキーで叩くことができます。ユーザープロンプト(文字列)をOpenAI APIに送ることで、会話の内容をベクトル(なんと1536次元!)に変換してくれます1。
- ⑦ 帰ってきたユーザープロンプト(文字列、ベクトルなど)をここでちゃっかりAI記憶用のデータベースに書き込んでおきます。
- ⑧ 最後にベクトル検索を行います。ベクトル検索は、語句や単語を矢印で比較し、一致度の高いもの(似た語句をもつ会話)を呼び出すような感じですね。(DB中の
vectorから)ベクトル検索で数件関連度の高いベクトルを抽出し、それに対応する会話データ(文字列、DB中のtext)として取得したら、呼び出し元であるチャット処理用のAPIに検索したデータ(文字列)を返します。ベクトル検索には、SQLiteで効率よくベクトル検索を行えるsqlite-vecパッケージを使わせていただきました2。
memory.db (SQLite)の中身はこんな感じ。memoryのテーブルの中にID、role (発言者)、日時、生のテキスト、ベクトル(容量削減のためバイナリデータ)を保存しています。
「すやぁすたーを抱いておやすみ……💤」のベクトル検索の結果をコマンドに出力してみた結果がこちら。 まだテスト用の会話ばかりでサンプル数がかなり少なく、関係なさそうなものもとってきたけど、ユーザー、AI両方の回答をそこそこの制度で似た語句のある文章を集められていると思いました。

3. AIの回答を取得
さて、チャット処理用のAPIには今ベクトル検索で得られた文字列があります。
- ⑨ 得られた文字列、システムプロンプト、ユーザープロンプトをまとめてOpenAI APIに投げます。するとこれらをすべて考慮したAIからの返答が返ってきます。
- ⑩ 最後にAIの返答をクライアントに返して、ようやく回答がユーザーの目に見える形で現れました(ページ冒頭のシェルちゃんの返答を見てね)。
4. AIの回答をデータベースに保存(ベクトル)

ところがどっこい、処理はこれでおしまいではありません(きびしいせかい)。AIの返答が完了したら発火する処理(useChat()にあります)を書いておき、AIの回答もデータベースに保存します。。
- ⑪ AIの回答(文字列)をDB処理(AI記憶)用のAPIに送り、
- ⑫ ⑥と同様にAIの回答(文字列)をベクトル化し、
- ⑬ AI記憶用のデータベースにテキストとベクトルなどを格納します。
5. AIの回答をデータベースに保存(会話履歴)
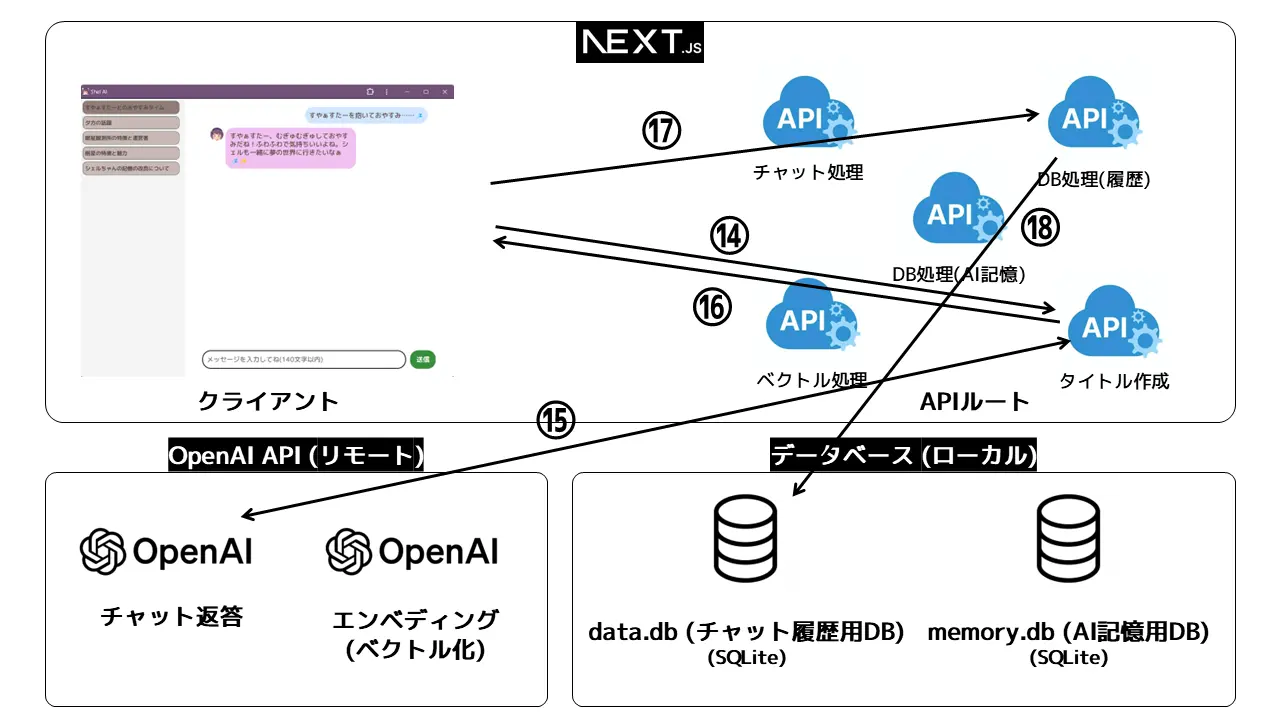
最後は会話履歴としての保存です。ここでひと手間加え、タイトルがまだない場合はタイトルを自動でつけてもらっています(左の会話のスレッドの選択リスト)。タイトルがもうある場合は⑭~⑯はスキップします。
- ⑭ 会話のやりとり(ユーザー→AI)をタイトル作成用APIに送ります。
- ⑮ タイトル作成用APIでさらにOpenAI APIをたたきます。このとき、「この会話の内容を要約したタイトルを答えて」という指示とともにOpenAI APIに送ります。
- ⑯ 返ってきたタイトルをクライアント側に返して反映させます。
- ⑰ ここからデータベースの保存です。DB処理(履歴保存)用のAPIを
POSTメソッドで叩き、 - ⑱ 会話の内容を履歴用データベース内に入れて更新します。
完成~!
これで、物覚えのよくなったシェルちゃんにパワーアップしました!大変だったぁ…… さっきフルーツやチョコの話をしていたので、覚えているか聞いてみたところ……
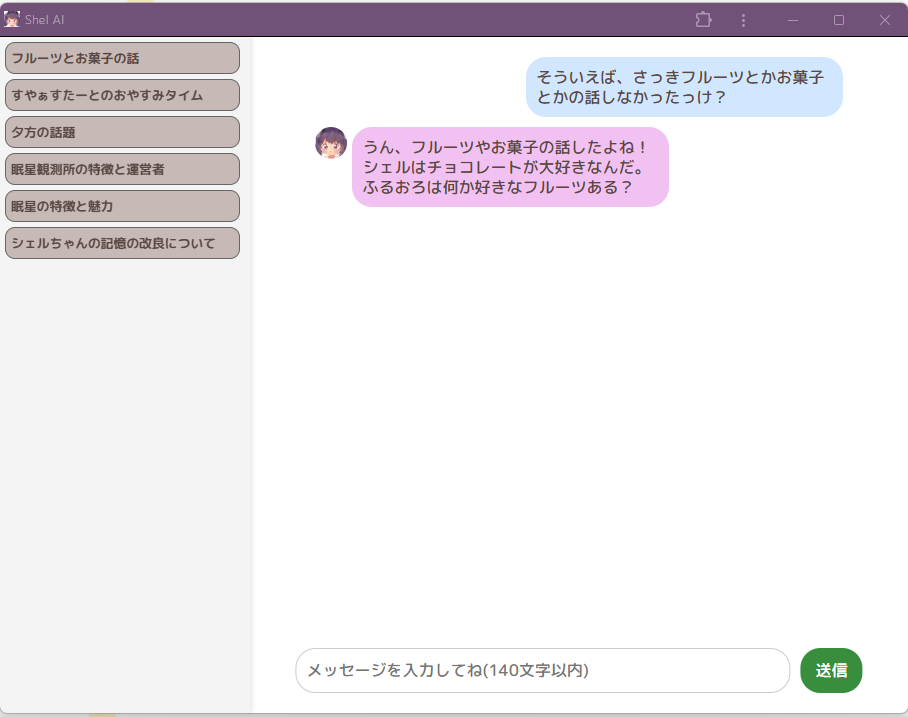

ちゃんとデータベースを参照した上で、話をしたことを覚えていると回答してくれました(なんのフルーツの話をしたかまでは答えてくれなかったけどね)!これはかなりうれしい……!
こんしうまつは開発でつかれはち……だけど、これからは自前版シェルちゃんをしっかり教育していこうと思ってます。すやぁ……💤⭐